Time-Contrastive Networks:
Self-Supervised Learning from Multi-View Observation
Pierre Sermanet*, Corey Lynch*†, Jasmine Hsu, Sergey Levine
Google Brain
(* equal contribution, † Google Brain Residency program g.co/brainresidency)
This project is part of the larger Self-Supervised Imitation Learning project.
Click here for an updated version of this project.
[ Paper ] [ BibTex ] [ Video ]

Abstract
We propose a self-supervised approach for learning representations entirely from unlabeled videos recorded from multiple viewpoints. This is particularly relevant to robotic imitation learning, which requires a viewpoint-invariant understanding of the relationships between humans and their environment, including object interactions, attributes and body pose. We train our representations using a triplet loss, where multiple simultaneous viewpoints of the same observation are attracted in the embedding space, while being repelled from temporal neighbors which are often visually similar but functionally different. This signal encourages our model to discover attributes that do not change across viewpoint, but do change across time, while ignoring nuisance variables such as occlusions, motion blur, lighting and background. Our experiments demonstrate that such a representation even acquires some degree of invariance to object instance. We demonstrate that our model can correctly identify corresponding steps in complex object interactions, such as pouring, across different videos with different instances. We also show what are, to the best of our knowledge, the first self-supervised results for end-to-end imitation learning of human motions by a real robot.
Model
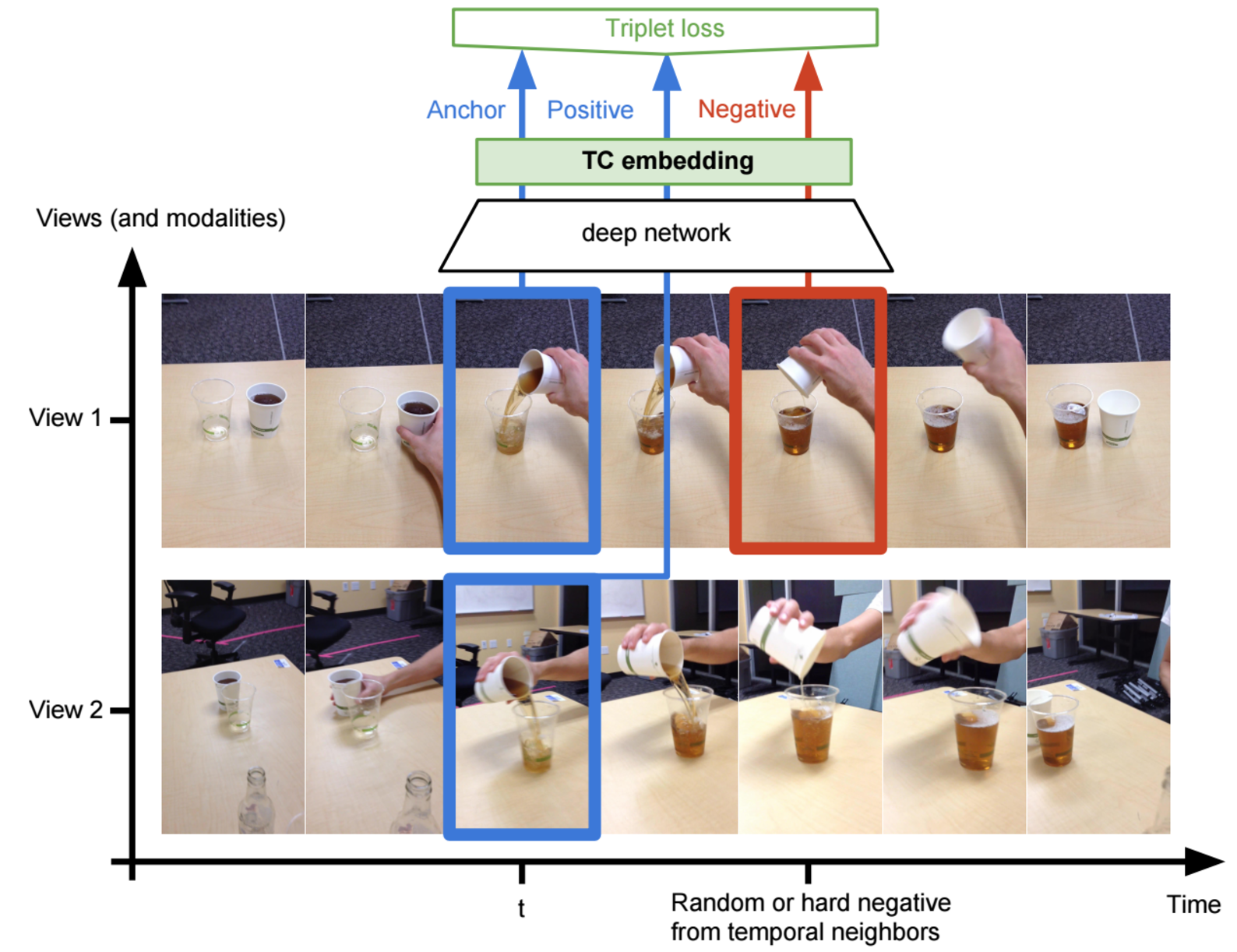
Unsupervised Objects Interactions
Training Sequences

Semantic Alignment / Nearest Neighbor Imitation

‘Fake’ pouring imitation

Imitation Errors

Robotic Imitation (end-effector never seen during training)

End-to-End Self-Supervised Pose Imitation
Self-supervised only (no labels)

Complex non-linear mapping discovered unsupervised (many-to-one joint mapping)

Imitation Failures (shoulder joint)

Self-supervision + human supervision

Citation
@article{TCN2017,
title={Time-Contrastive Networks: Self-Supervised Learning from Multi-View Observation},
author={Sermanet, Pierre and Lynch, Corey and Hsu, Jasmine and Levine, Sergey},
journal={arXiv preprint arXiv:1704.06888},
year={2017}
}
Acknowledgments
We thank Jonathan Tompson, James Davidson and Vincent Vanhoucke for helpful discussions and feedback. We are also grateful to Eric Jang and Phing Lee for their repeated help and talent in robot imitation. Finally we thank everyone else who provided imitations for this project: Alexander Toshev, Anna Goldie, Deanna Chen, Deirdre Quillen, Dieterich Lawson, Eric Langlois, Ethan Holly, Irwan Bello, Jasmine Collins, Jeff Dean, Julian Ibarz, Ken Oslund, Laura Downs, Leslie Phillips, Luke Metz, Mike Schuster, Ryan Dahl, Sam Schoenholz and Yifei Feng.